🛠️Como fiz esse site
Este site foi desenvolvido utilizando a combinação poderosa do 🔧 Jekyll, o tema 🎨 Minimal e scripts em 🐍 Python. A minha intenção era criar uma plataforma para exibir de forma automática e organizada os meus artigos no 💼 Linkedin, os Gists no 🐙 Github e até mesmo os meus livros no 📚 Goodreads.
Jekyll e Minimal 🖌️
O Jekyll é um gerador de sites estáticos que simplifica o processo de criação e manutenção de sites. Com o Jekyll, pude tirar proveito das suas funcionalidades de compilação automática, gerenciamento de layouts e facilidade na criação de páginas dinâmicas.
O tema Minimal foi escolhido como base para o design deste site. Sua estética limpa e minimalista se encaixou perfeitamente com a proposta do site. O tema Minimal também oferece uma estrutura bem organizada, com diferentes seções que facilitaram a apresentação de conteúdo de maneira clara e intuitiva.
Scripts em Python 🐍
A personalização desse site envolveu a escrita de scripts em Python para compilar e integrar o conteúdo das minhas diferentes plataformas. Eu criei esses scripts para extrair os artigos do Linkedin, os Gists do Github e os dados dos meus livros no Goodreads. Com esses dados em mãos, o Jekyll se encarregou de renderizar as páginas estáticas de acordo com o layout definido pelo tema Minimal.
A escolha do Python como linguagem de programação se deu pela sua versatilidade e pela ampla gama de bibliotecas disponíveis para manipulação de dados, web scraping e integração com APIs. Essas características foram essenciais para automatizar o processo de coleta de dados e tornar a atualização do site mais eficiente.
Compartilho aqui um dos scripts que transforma o HTML fornecido pelo Linkedin em uma solicitação de meus dados pessoais, em um arquivo markdown no formato adequado para o Jekyll:
import json
import os
import shutil
from bs4 import BeautifulSoup
from markdownify import markdownify
from unidecode import unidecode
# Caminho para o diretório do LinkedIn Archive
linkedin_archive_path = './resources/'
# Caminho para o diretório de saída das páginas Jekyll
output_path = './'
# Processar posts
posts_directory = os.path.join(linkedin_archive_path, 'Articles/Articles')
if os.path.exists(posts_directory):
# Criar diretório de saída para os posts das páginas Jekyll
jekyll_posts_directory = os.path.join(output_path, '_posts')
os.makedirs(jekyll_posts_directory, exist_ok=True)
# Iterar sobre os arquivos de posts no diretório do LinkedIn Archive
for filename in os.listdir(posts_directory):
post_file = os.path.join(posts_directory, filename)
if os.path.isfile(post_file):
with open(post_file, 'r') as f:
post_data = f.read()
# Parsear o conteúdo HTML do post
soup = BeautifulSoup(post_data, 'html.parser')
# Extrair o título do post
title_element = soup.find('h1')
if title_element:
title_link = title_element.find('a')
if title_link:
title = title_link.text.strip()
else:
title = title_element.text.strip()
else:
title = "No Title"
# Se não há título, pular para o próximo post
if title == "No Title":
continue
# Extrair a data de criação e publicação do post
created = soup.find('p', class_='created').text.split('on ')[1].strip()
published = soup.find('p', class_='published').text.split('on ')[1].strip()
#Não publica rascunhos
if len(published) < 5:
continue
# Extrair o conteúdo do post e convertê-lo para Markdown
content = soup.find('div').prettify()
markdown_lines = content.splitlines()
markdown_content = "\n".join(line.strip() for line in markdown_lines)
# Criar arquivo de post no formato Jekyll
# Omitir a data e hora do valor de created
created_date = created.split()[0]
jekyll_post_filename = f"{created_date.replace(' ', '_')}-{unidecode(title).replace(' ', '-').replace(':', 'h').lower()}.markdown"
jekyll_post_file = os.path.join(jekyll_posts_directory, jekyll_post_filename)
with open(jekyll_post_file, 'w') as jekyll_f:
jekyll_f.write('---\n')
jekyll_f.write(f"layout: post\n")
jekyll_f.write(f"language: pt\n")
jekyll_f.write(f"categories: artigos\n")
# Verificar se o título contém ":" e substituir por "-"
jekyll_f.write(f"title: {title.replace(':', '-')}\n")
jekyll_f.write(f"url: {unidecode(title).replace(' ', '-').lower()}\n")
jekyll_f.write(f"date: {created}\n")
jekyll_f.write('---\n')
jekyll_f.write(markdown_content)
print(f"Criado o arquivo {jekyll_post_filename}")
Hospedagem no GitHub Pages 🌐
Este site está hospedado no GitHub Pages, uma plataforma de hospedagem gratuita fornecida pelo GitHub. O GitHub Pages permite a publicação direta de sites estáticos a partir de repositórios do GitHub. Com a integração entre o Jekyll e o GitHub Pages, foi possível automatizar a compilação e a atualização do site sempre que houver alterações no código ou nos dados.
Espero que essa breve explicação sobre o desenvolvimento deste site tenha sido útil.
Obrigado por visitar! 😊
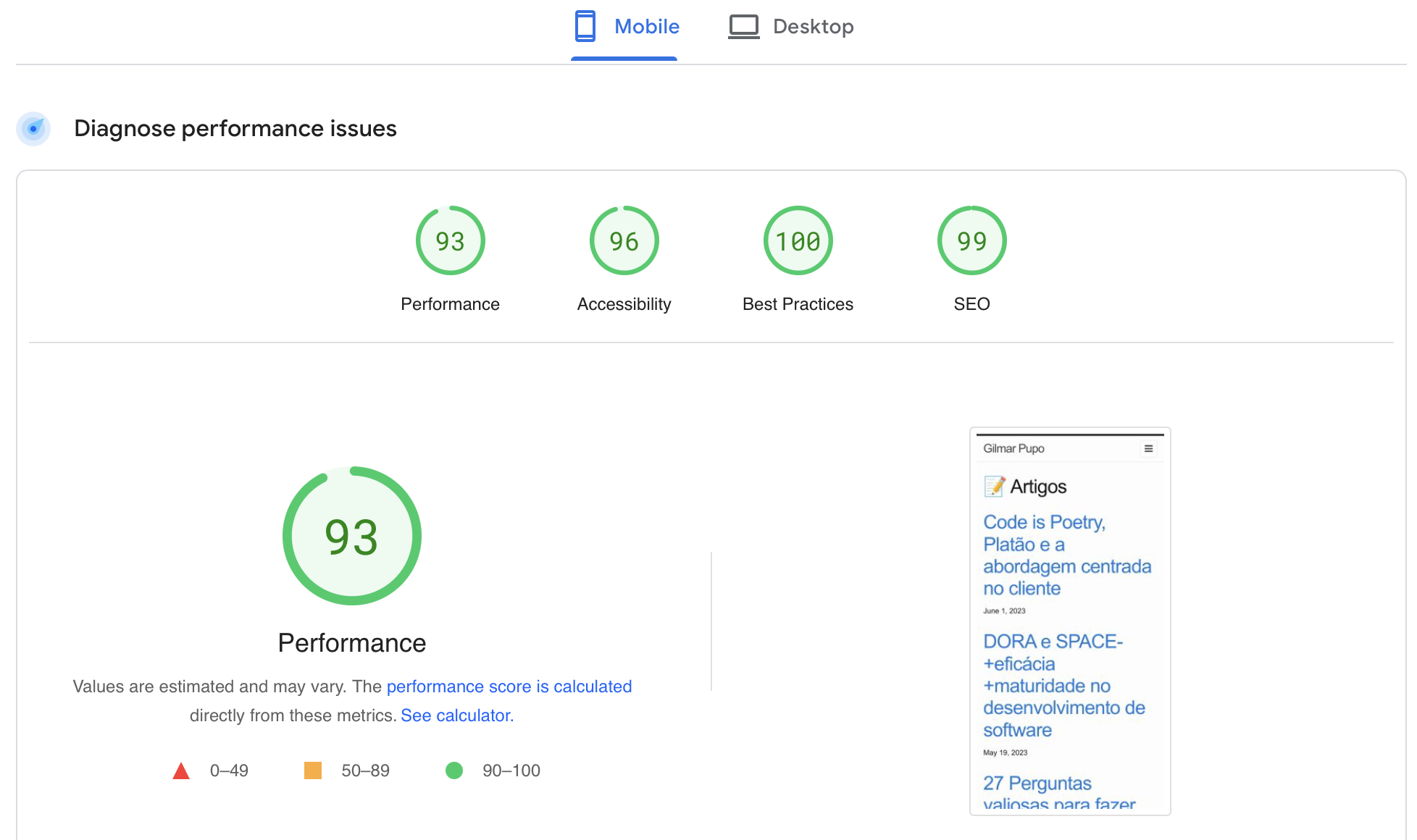
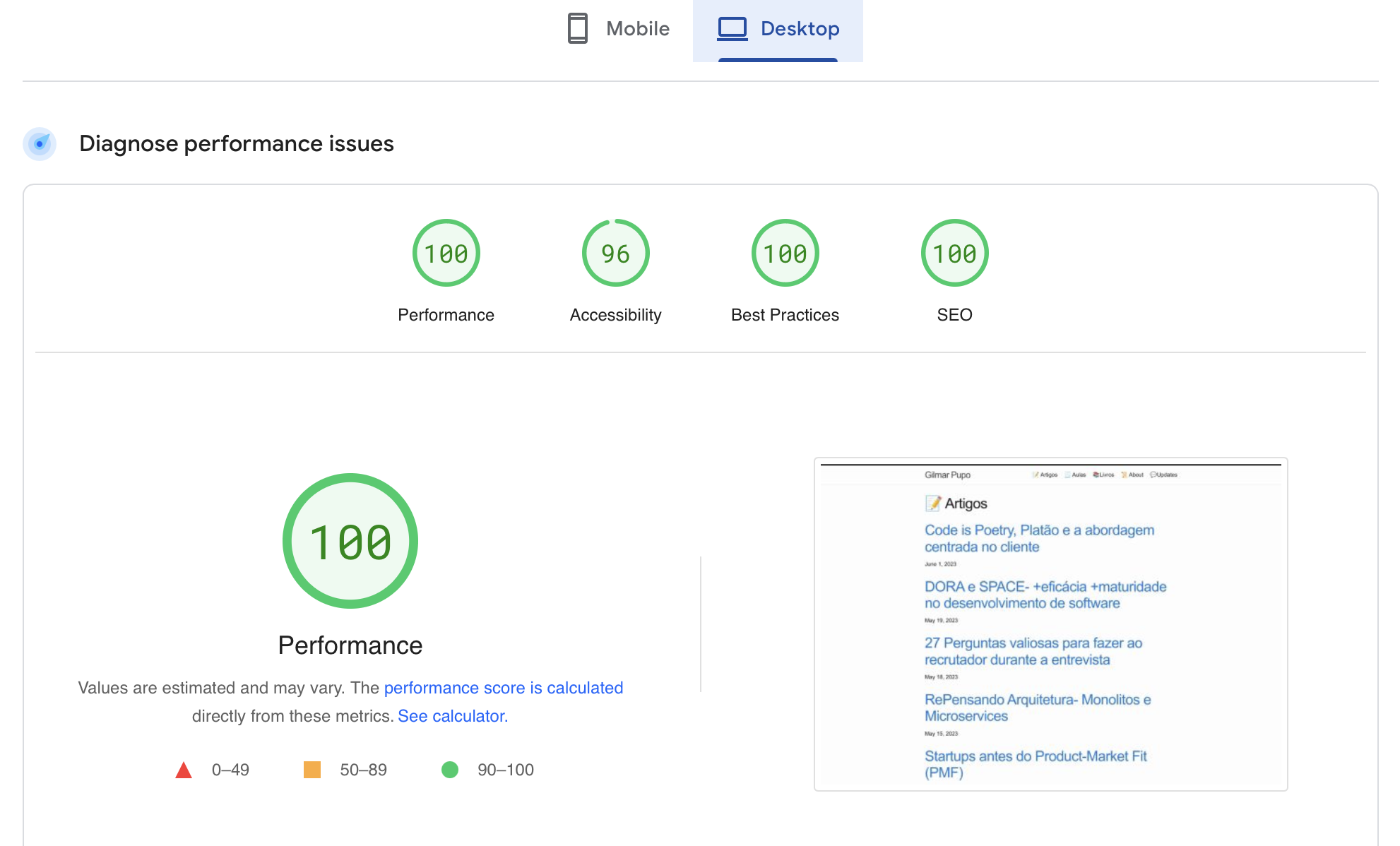
Page Speed
Pagespeed report: